EmbodiedBench
A comprehensive benchmark for evaluating multi-modal large language models as vision-driven embodied agents across diverse environments and task complexities.
EmbodiedBench
Overview
EmbodiedBench is a standardized evaluation platform designed to comprehensively assess multi-modal large language models (MLLMs) functioning as embodied agents. Our benchmark evaluates agents across diverse environments and varying task complexities, providing a rigorous framework for understanding MLLM capabilities in embodied AI scenarios.
Overview of EmbodiedBench showing various action levels and capability-oriented evaluation
Key Contributions
Comprehensive Evaluation Framework
- Four Environments: EB-ALFRED, EB-Habitat, EB-Navigation, and EB-Manipulation
- Six Critical Capabilities: Task solving, reasoning, instruction understanding, spatial awareness, perception, and planning
- Hierarchical Task Design: Evaluates both high-level and low-level embodied tasks
Unified Agent Pipeline
Our framework processes multimodal inputs through a standardized pipeline:
- Visual perception of the environment
- Natural language instruction understanding
- Spatial reasoning and planning
- Action generation and execution
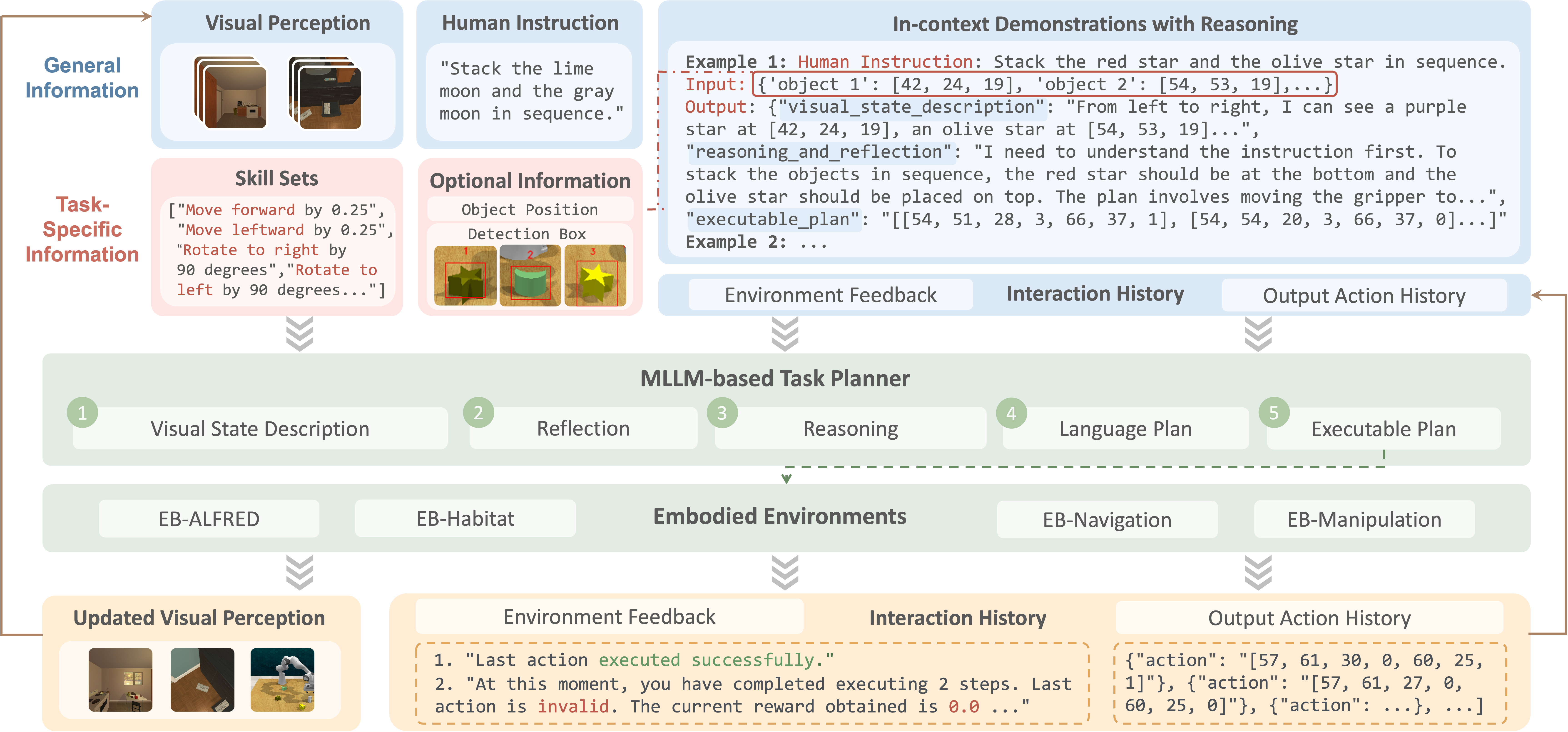 Vision-driven agent pipeline used in EmbodiedBench
Vision-driven agent pipeline used in EmbodiedBench
Error Analysis
We provide detailed failure mode analysis across three key categories:
- Perception Errors: Visual understanding and object recognition failures
- Reasoning Errors: Logical inference and task decomposition issues
- Planning Errors: Action sequence and goal-oriented planning problems
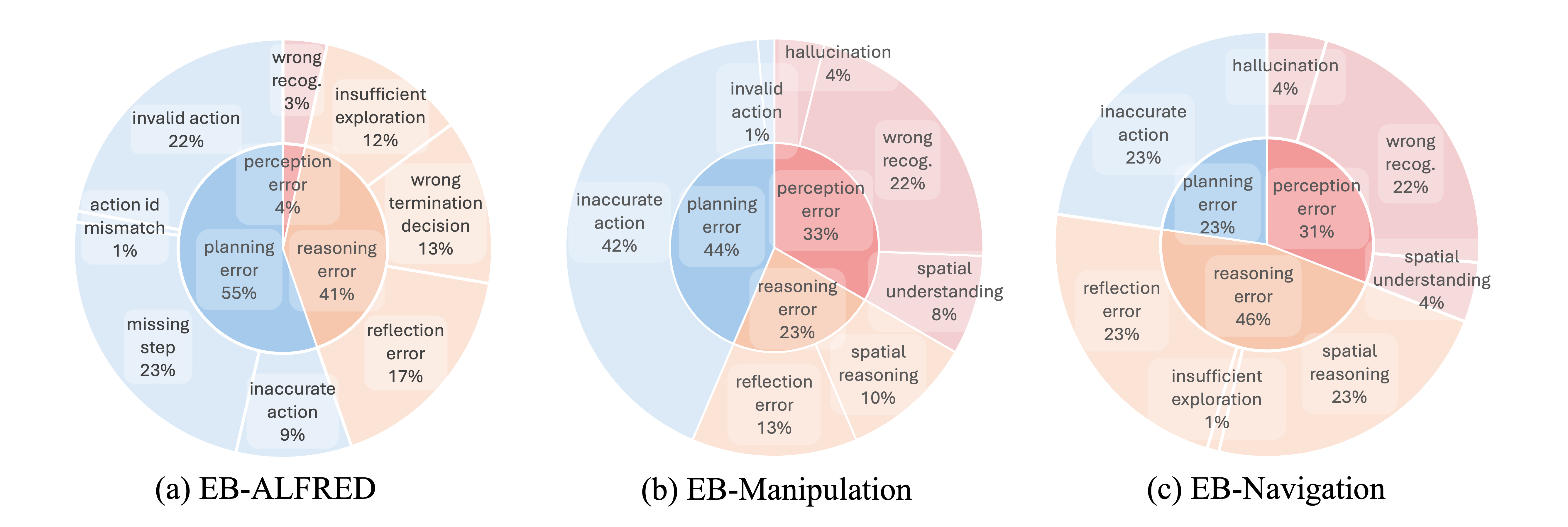 Categorization of perception, reasoning, and planning error types
Categorization of perception, reasoning, and planning error types
Evaluation Results
EmbodiedBench evaluates state-of-the-art MLLMs including:
- GPT-4o
- Claude-3.5-Sonnet
- Gemini-1.5-Pro
- InternVL2.5-78B
Our comprehensive analysis reveals performance variations across different model architectures and identifies key areas for improvement in embodied AI research.
Successful Examples
 Claude-3.5-Sonnet successfully completing EB-ALFRED task
Claude-3.5-Sonnet successfully completing EB-ALFRED task
 InternVL2.5-78B successfully navigating EB-Habitat environment
InternVL2.5-78B successfully navigating EB-Habitat environment
 GPT-4o performing navigation tasks
GPT-4o performing navigation tasks
 Gemini-1.5-Pro handling manipulation challenges
Gemini-1.5-Pro handling manipulation challenges
Resources
- Paper: arXiv:2502.09560
- Website: https://embodiedbench.github.io/
- Code: GitHub Repository
- Dataset: Available on HuggingFace
Authors
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, Tong Zhang
Affiliations: University of Illinois Urbana-Champaign, Northwestern University, University of Toronto, Toyota Technological Institute at Chicago
Citation
Accepted at ICML 2025 (Oral Presentation)
bibtex@article{yang2025embodiedbench, title={EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents}, author={Yang, Rui and Chen, Hanyang and Zhang, Junyu and Zhao, Mark and Qian, Cheng and Wang, Kangrui and Wang, Qineng and Koripella, Teja Venkat and Movahedi, Marziyeh and Li, Manling and Ji, Heng and Zhang, Huan and Zhang, Tong}, journal={arXiv preprint arXiv:2502.09560}, year={2025} }